- Introduction au Deep Learning
- Comment les algorithmes de Deep Learning “apprennent-ils” ?
- Convolutional Neural Network (CNN)
- Conduite autonome utilisant l’apprentissage profond et le clonage comportemental
Introduction au Deep Learning
Au cours des dernières années, Deep Learning est devenu un mot à la mode dans le milieu de la technologie. Nous semblons toujours en entendre parler dans les nouvelles concernant l’IA, et pourtant la plupart des gens ne savent pas vraiment ce que c’est !
Définition: Le Deep Learning est un sous-domaine de machine- learning qui traite des algorithmes inspirés par la structure et la fonction du cerveau appelés réseaux neuronaux artificiels. En d’autres termes, il reflète le fonctionnement de notre cerveau. Les algorithmes d’apprentissage profond sont semblables à la façon dont le système nerveux se structure là où chaque neurone se connecte et transmet l’information.
Cette méthode d’apprentissage prend une entrée X et l’utilise pour prédire une sortie de Y. Par exemple, étant donné les cours des actions de la semaine passée comme entrée, mon algorithme de deep learning va essayer de prédire le cours des actions du jour suivant. Étant donné le grand nombre de paires d’entrées et de sorties, un algorithme du Deep Learning tentera de minimiser la différence entre sa prédiction et le résultat attendu. En faisant cela, il essaie d’apprendre l’association/modèle entre des entrées et des sorties données - ce qui permet à son tour à un modèle d’apprentissage profond de généraliser à des entrées qu’il n’a jamais vues auparavant.
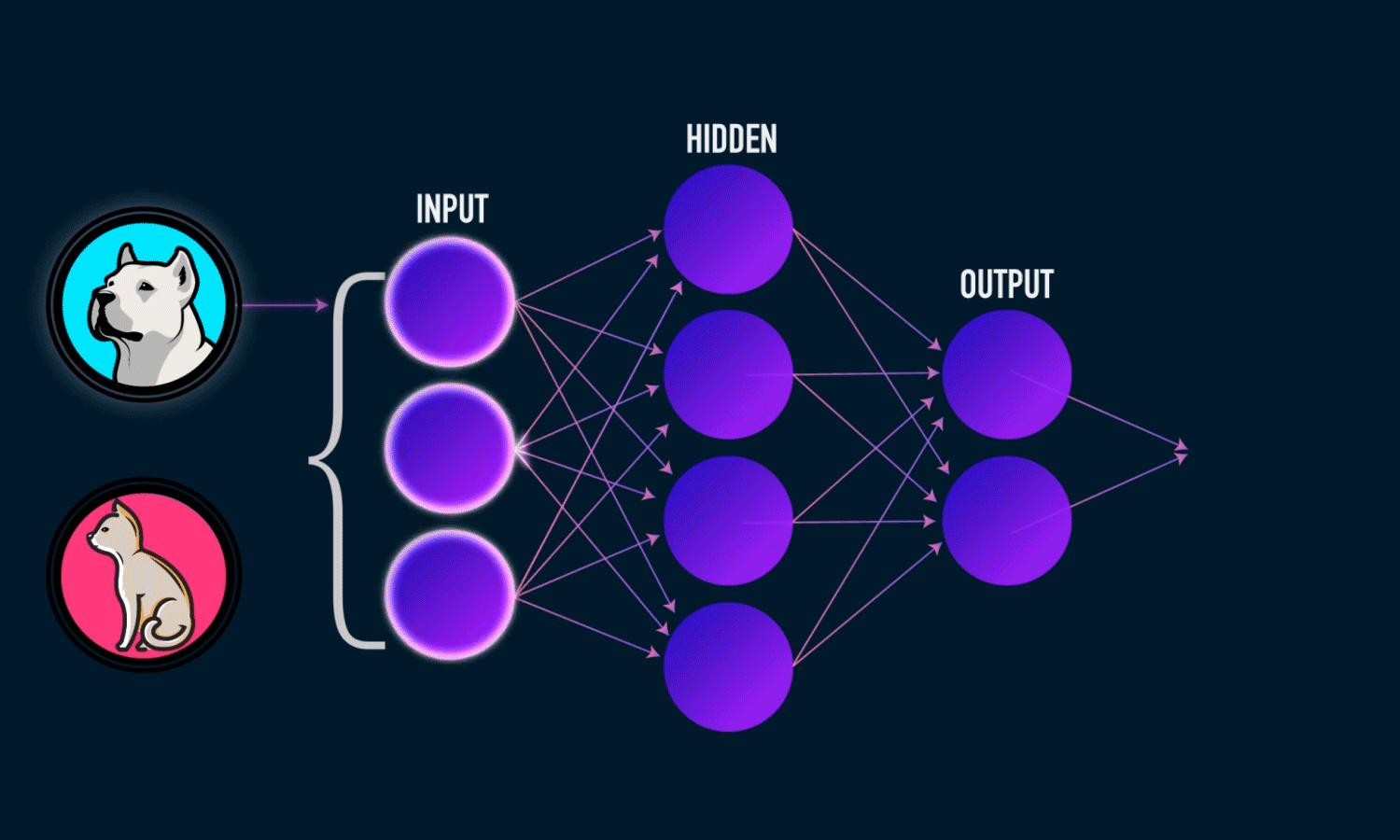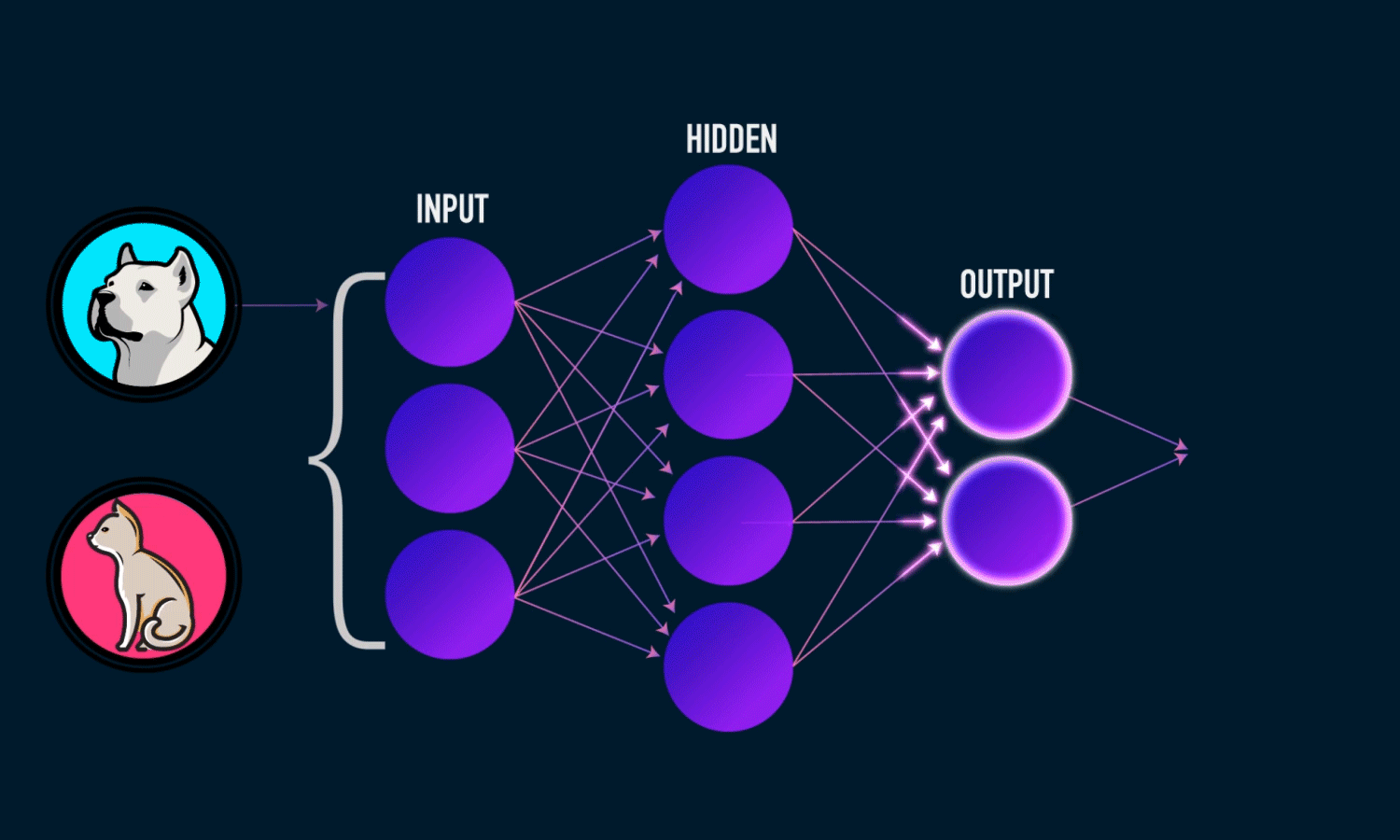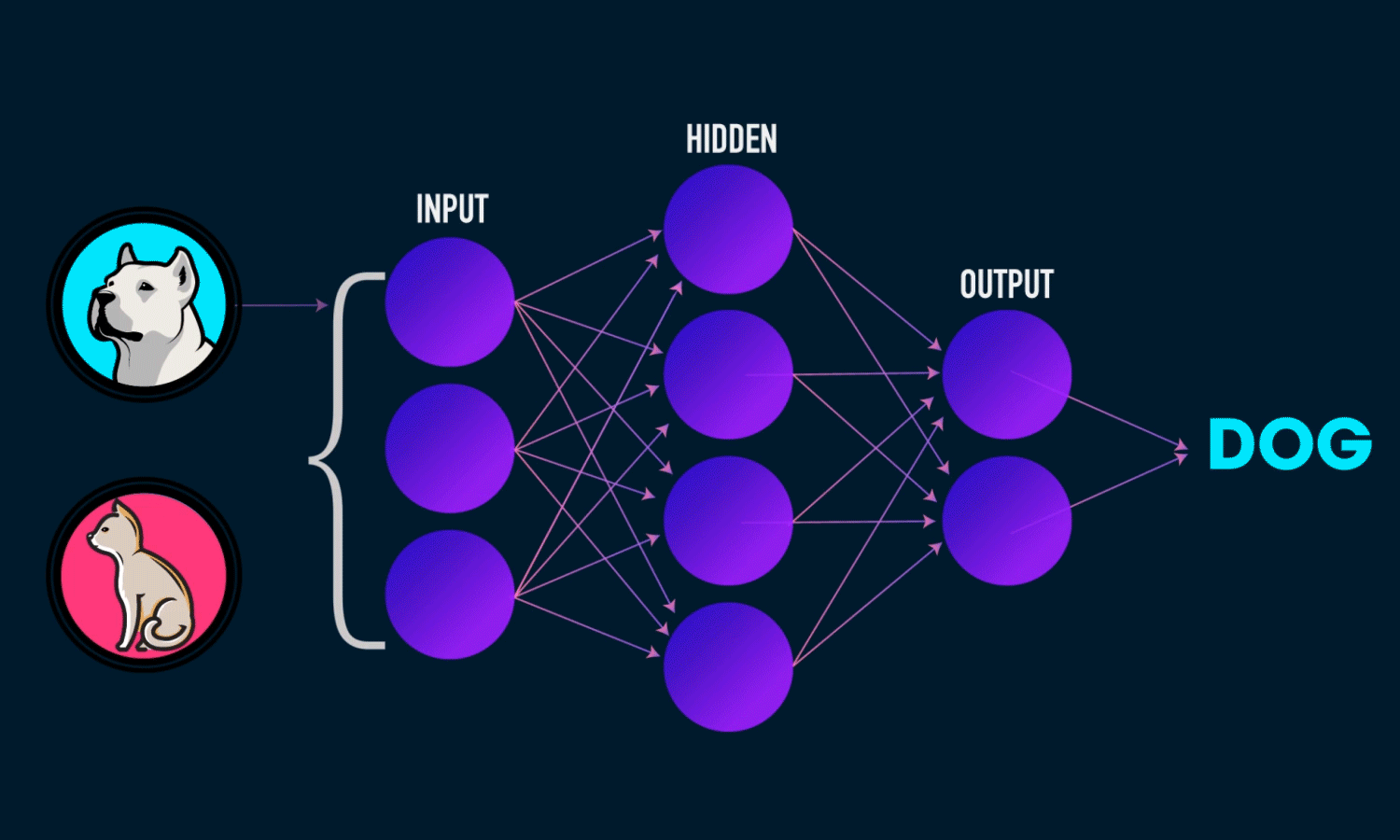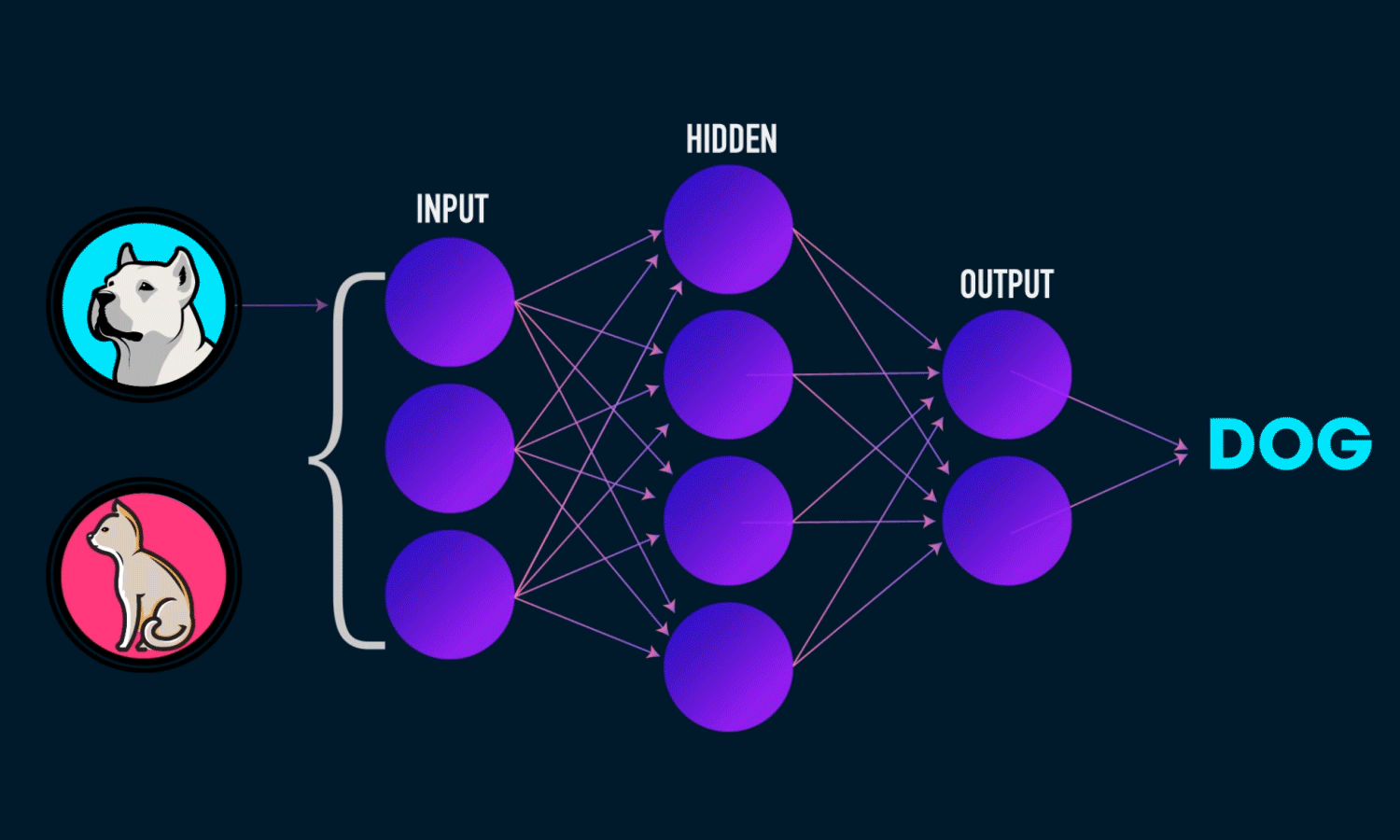
Prenons un autre exemple, disons que les entrées sont des images de chiens et de chats, et les sorties sont des étiquettes pour ces images (c.-à-d. l’image d’entrée est-elle un chien ou un chat). Si une entrée a l’étiquette d’un chien, mais que l’algorithme d’apprentissage profond prédit un chat, alors mon algorithme d’apprentissage profond apprendra que les caractéristiques de mon image donnée (par exemple, dents pointues, traits du visage) vont être associées à un chien.
Comment les algorithmes de Deep Learning “apprennent-ils” ?
Les algorithmes de Deep Learning utilisent ce qu’on appelle un réseau neuronal pour trouver des associations entre un ensemble d’entrées et de sorties. La structure de base est présentée ci-dessous :
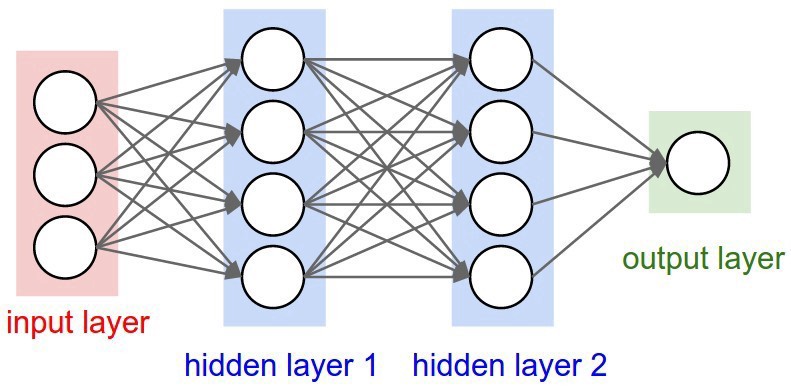
Un réseau neuronal est composé de couches d’entrée, de couches cachées et de couches de sortie - qui sont toutes composées de “nœuds”. Les couches d’entrée prennent en compte une représentation numérique des données (par exemple des images avec des spécifications en pixels), les couches de sortie donnent les prédictions, tandis que les couches cachées sont corrélées avec la majeure partie du calcul.
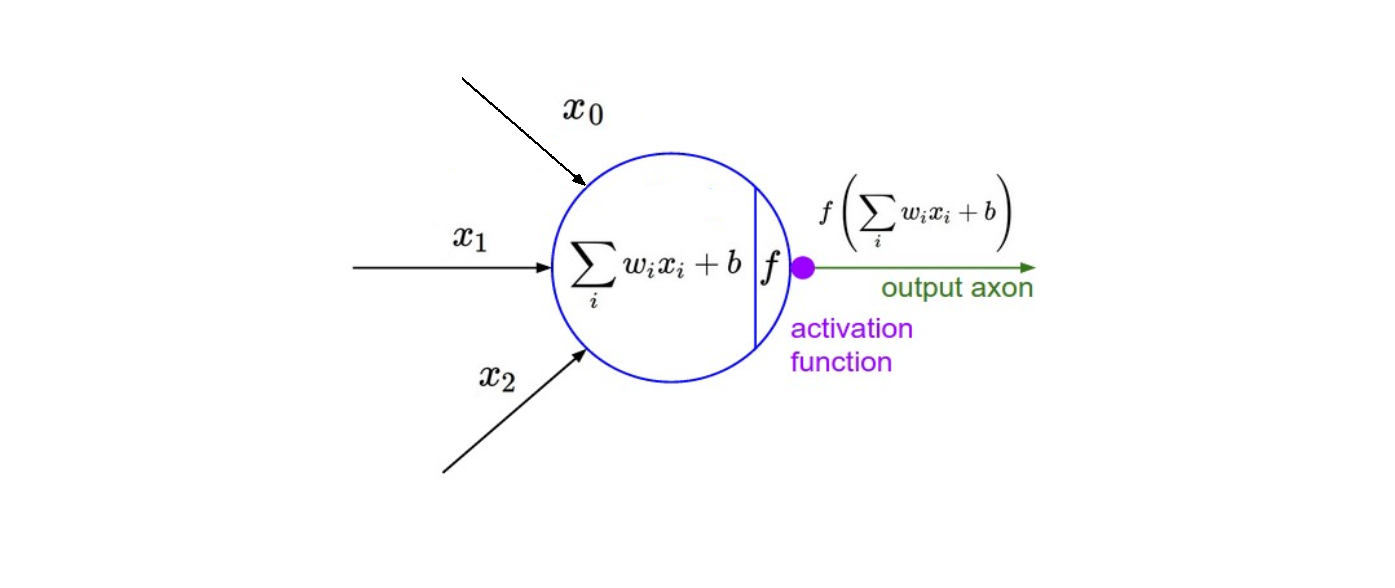
Je ne vais pas aller trop dans les détails du maths, mais l’information est transmise entre les couches du réseau par la fonction montrée ci-dessus. Les principaux points à noter ici sont les paramètres de poids et de biais réglables - représentés par w et b respectivement dans la fonction ci-dessus. Ils sont essentiels au processus d’“apprentissage” d’un algorithme du Deep Learning.
Après que le réseau neuronal a transmis ses entrées à ses sorties, le réseau évalue la qualité de sa prédiction (par rapport à la sortie attendue) par le biais d’une fonction dite de perte. A titre d’exemple, la fonction de perte “Mean Squared Error” qui est illustrée ci-dessous.
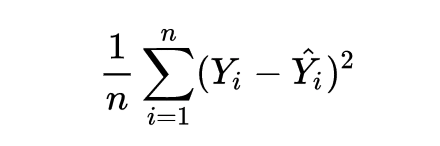
Y chapeau représente la prédiction, tandis que Y représente le résultat attendu. Une moyenne est utilisée si des batchs d’entrées et de sorties sont utilisés simultanément (n représente le nombre d’échantillons).
Le but ultime de mon réseau est de minimiser cette perte en ajustant les poids et les biais du réseau. En utilisant ce que l’on appelle la “ rétropropagation “ par descente de gradient, le réseau recule à travers toutes ses couches pour mettre à jour les poids et les biais de chaque nœud dans la direction opposée de la fonction de perte - en d’autres termes, chaque itération de la rétropropagation devrait aboutir à une fonction de perte plus faible que précédemment.
Sans entrer dans la preuve, les mises à jour continues des poids et des biais du réseau en font en fin de compte un approximateur de fonction précis, qui modélise la relation entre les entrées et les sorties attendues.
Convolutional Neural Network (CNN)
Les réseaux neuronaux convolutionnels (ConvNets ou CNNs) sont l’une des principales catégories de réseaux de neuronaux. Cette catégorie sert pour faire la reconnaissance d’images, la classification des images. La détection d’objets, les visages de reconnaissance, etc. sont quelques-uns des domaines où les CNN sont largement utilisés.
La classification d’images par CNN prend une image d’entrée, la traite et la classe dans certaines catégories (par exemple, chien, chat, tigre, lion). Les ordinateurs voient une image d’entrée comme un tableau de pixels et cela dépend de la résolution de l’image. En fonction de la résolution de l’image, il verra h x l x d( h = Hauteur, l = Largeur, d = Dimension). Par exemple, une image de 6 x 6 x 3 x 3 matrice de matrice de RVB (3 se réfère aux valeurs RVB) et une image de 4 x 4 x 1 matrice de matrice d’image en niveaux de gris.
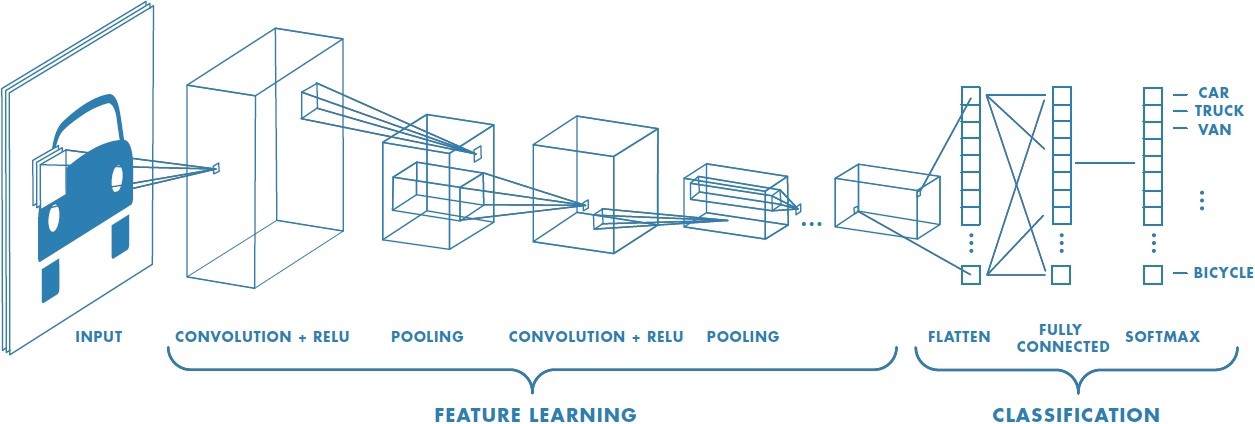
Techniquement, chaque image d’entrée passera à travers une série de couches de convolution avec filtres (Kernals), Pooling, de couches entièrement connectés (FC) suivis par une fonction d’activation Softmax pour classer un objet avec des valeurs probabilistes entre 0 et 1. la figure ci-dessous est un flux complet CNN pour traiter une entrée d’image et classer les objets en fonction des valeurs.
La Couche de convolution
La convolution est le premier couche qui extrait les caractéristiques d’une image d’entrée. La convolution préserve la relation entre les pixels en apprenant les caractéristiques de l’image à l’aide de petits carrés de données d’entrée. Il s’agit d’une opération mathématique qui nécessite deux entrées telles qu’une matrice d’image et un filtre ou kernel.

Considérons une image 5 x 5 dont les valeurs de pixels sont 0, 1 et la matrice de filtrage 3 x 3 comme indiqué ci-dessous:
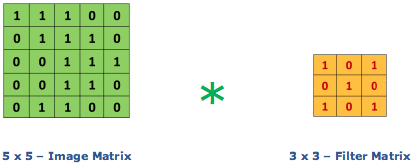
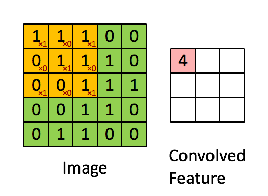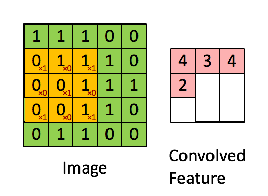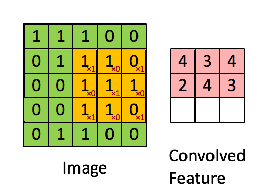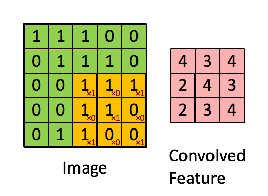
Alors la convolution de la matrice d’image 5 x 5 se multiplie avec la matrice de filtre 3 x 3 qui s’appelle “Feature Map”. La sortie est montrée ci-dessous:
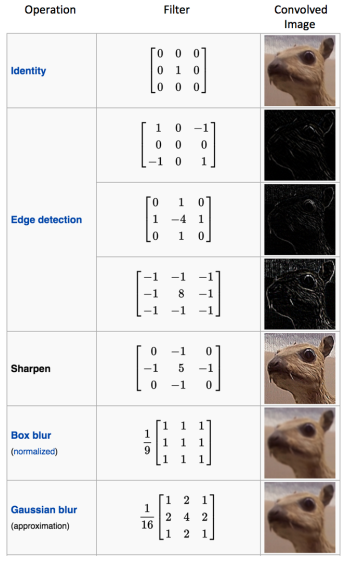
La convolution d’une image avec différents filtres permet d’effectuer des opérations telles que la détection des contours, rendre une image plus floue ou plus nette en appliquant des filtres. L’exemple ci-dessous montre différentes images de convolution après application de différents types de filtres (noyaux).
Conduite autonome utilisant l’apprentissage profond et le clonage comportemental
Génération de données pour le système autonome
Cette partie est inspirée du processus de collecte de données de Nvidia Self-Driving Car. Ils ont attaché 3 caméras à une voiture. L’un est placé au centre et les 2 autres sont placés de chaque côté de la voiture. Ils ont enregistré les données du volant, capturant l’angle de braquage.
Le volant est fixé au système via le Controller Area Network (CAN) pour alimenter la valeur du volant, de l’accélérateur, du frein. Les caméras sont également connectées au système où elles sont alimentées en flux continu de données vidéo. Le système s’appelle Nvidia Drive PX - Nvidia Drive est une plate-forme AI qui permet aux utilisateurs de construire et de déployer des voitures, des camions et des navettes à conduite automatique. Il combine l’apprentissage en profondeur, les capteurs de fusion pour changer l’expérience de conduite. Un Solid State Drive est utilisé pour stocker toutes les données collectées. Udacity ont developpé un simulateur d’auto-conduite qui fait la même chose.
Vous trouverez le simulateur ici. C’est un fichier binaire ! Vous n’avez pas à vous soucier de le compiler. Il suffit de double-cliquer dessus et le simulateur démarre ! C’est trop cool !
Le simulateur a 2 modes - Mode d’apprentissage et mode Autonome :

Le mode d’entraînement ressemble à ceci :

En mode d’entraînement, le simulateur capture les images des 3 caméras, la valeur de vitesse, la valeur d’accélération, la valeur de freinage et l’angle de braquage. Vous devez cliquer sur l’icône d’enregistrement en haut à droite de l’écran pour démarrer l’enregistrement.
Le mode autonome ressemble à ceci :

Dans ce mode, le simulateur agit comme un serveur et le script python agit comme un client. Vous comprendrez ce que je veux dire en lisant ce qui suit.
Entraînement du système autonome
Les données collectées au cours de la partie Génération de données impliquaient la collecte de toutes les images de la caméra, de l’angle de braquage et autres pendant qu’un conducteur humain conduisait la voiture. Nous pouvons créer un modèle qui clone la façon dont l’être humain conduisait la voiture, qui clone essentiellement le comportement du conducteur dans différents scénarios routiers. C’est ce qu’on appelle le clonage comportemental. Le clonage comportemental est une méthode qui permet de saisir et de reproduire les habiletés sous-cognitives humaines dans un programme d’ordinateur.
Vous trouverez ci-dessous une représentation graphique du fonctionnement de l’entraînement :
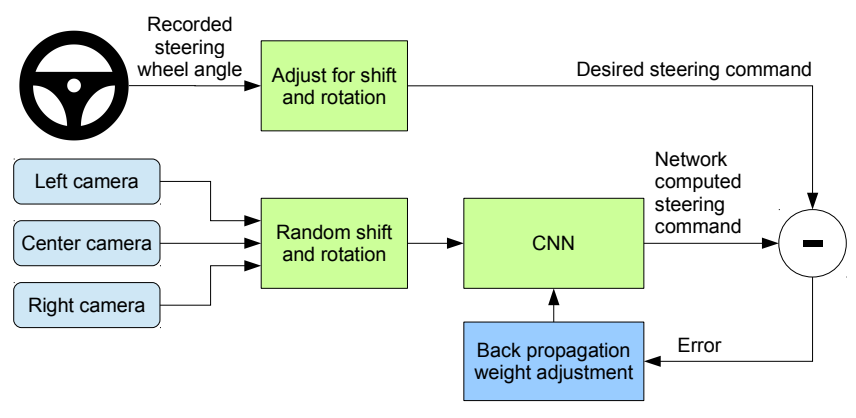
Les images capturées par les 3 caméras sont décalées au hasard et pivotées, puis envoyées au réseau neuronal. Sur la base de ces données, le réseau neuronal émettrait une valeur unique, l’angle de braquage. Essentiellement, en se basant sur les images d’entrée, le neurone neural décide de l’angle sous lequel la voiture doit être dirigée. Cette valeur de sortie est comparée aux données de pilotage recueillies lors de la conduite humaine pour calculer l’erreur dans la décision du réseau neuronal. Avec cette erreur, le modèle utilise l’algorithme Backpropogation pour optimiser le paramètre (poids) du modèle afin de réduire cette erreur.
L’architecture CNN(Convolutional Neural Network) la plus utilisée celle de Nvidia. Voici à quoi ressemble le réseau :
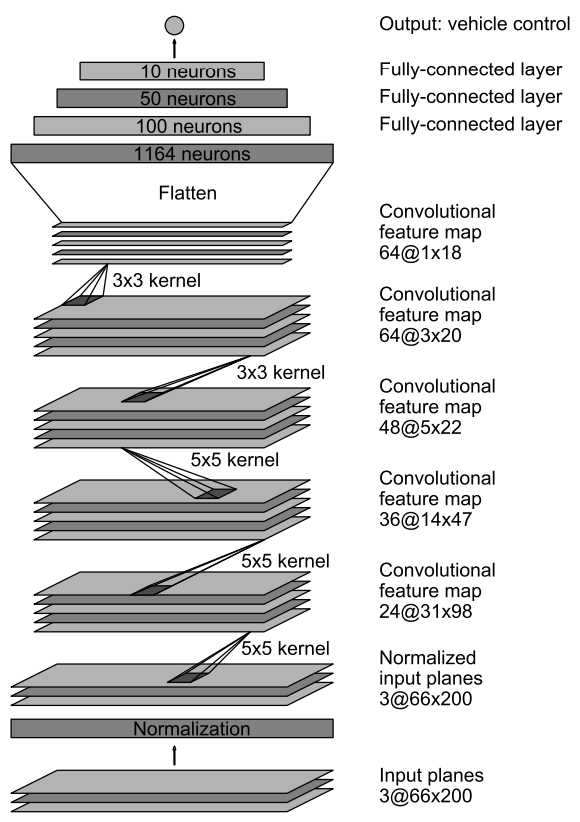
Le réseau se compose de 9 couches - une couche de normalisation, 5 couches convolutionnelles et 3 couches entièrement connectées. L’image d’entrée est convertie en YUV. La première couche normalise l’image. Les valeurs de normalisation sont codées en dur et ne sont pas entraînables. Les couches convolutionnelles effectuent l’extraction des caractéristiques. Les 3 premières couches utilisent des convolutions stridées avec un noyau de 5×5, et les 2 dernières couches convolutionnelles utilisent une convolution non stridée avec une taille de noyau de 3×3. Les couches convolutives sont suivies de 3 couches entièrement connectées. Les couches entièrement connectées sont censées agir comme un contrôleur pour le système autonome. Mais, étant donné l’apprentissage de bout en bout de l’ensemble du réseau, il est difficile de dire si les couches entièrement connectées sont les seules responsables du contrôleur.
Tester le système autonome
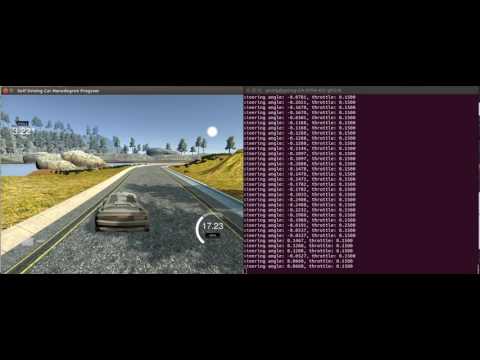
Le test se fait en utilisant uniquement les images de la caméra centrale. L’entrée de la caméra centrale est transmise au réseau de neurones, le réseau de neurones transmet la valeur de l’angle de braquage, cette valeur est transmise à la voiture autonome. Le simulateur de voiture autonome d’Udacity suit l’architecture Server-Client comme suit :
Le serveur sera le simulateur et le client sera le réseau neuronal, ou plutôt le programme Python. Tout ce processus est une boucle de rétroaction cyclique. Le simulateur affiche les images, le programme python les analyse et affiche l’angle de braquage et l’accélération. Le simulateur le reçoit et fait tourner la voiture en conséquence. Et tout le processus se déroule de manière cyclique.
Résultats
Voici une vidéo de la façon dont le réseau neuronal formé conduit la voiture :